What does the Turnitin Similarity Report mean?
Staff video guide to viewing and interpreting similarity reports.
Turnitin generates a Similarity Report based on how much text in the students paper matches that of the sources in Turnitin's database. A Similarity Report that Turnitin generates will look like the one below:
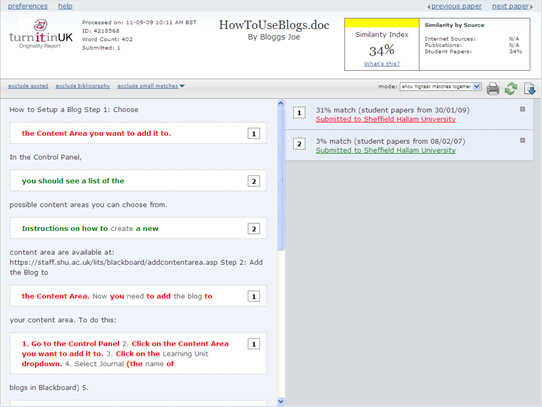
The student's submitted paper is on the left, with the sources identified as matches on the right hand side. The percentage of text in the student's work that matches that from each source is displayed. The total text taken from that source may be split up throughout the paper. The Similiary Index is an accumulation of all the individual percentage matches.
If you click on a source on the left, it will bring up the original work in a frame on the right. If the matching source is that of a student outside of the class or at a different university, you will not automatically see the original source. You can request access to the source, but granting access is at the discretion of a tutor for whom that student is in their class.
Please note that Turnitin does not discriminate between properly referenced text and plagiarised text. It just highlights text that you should look at further and evaluate. There are sources you might expect to match (quotes, references, etc.) and other sources that are 'false matches' of only a few words. These can be excluded and this will often reduce the percentage of text that matches each source, and subsequently the overall Similarity Index.
Further information
Turnitin guidance is available for students on the Hallam Digital Skills site.